Select
SELECT column1, column2, ...
FROM table_name;
SELECT * FROM table_name;
Select Distinct
Uvnitř tabulky sloupec často obsahuje mnoho duplicitních hodnot a někdy je třeba vypsat jen jiné hodnoty.
SELECT DISTINCT column1, column2, ...
FROM table_name;
Where
Where je používano k filtrování záznamů
SELECT column1, column2, ...
FROM table_name
WHERE condition;
And, Or, Not
Where může být kombinováno s AND, OR nebo NOT AND a OR operátory jsou používány k filtrování více záznamu na základě více podmínek
- AND operátor se zobrazí pokud všechny podmínky oděleny AND a jsou TRUE
- OR operátor se zobrazí pokud jakýkoliv podmínka je odělena OR je TRUE
NOT operátor se zobrazuje pokud podmínka není pravda
AND
SELECT column1, column2, ...
FROM table_name
WHERE condition1 AND condition2 AND condition3 ...;
OR
SELECT column1, column2, ...
FROM table_name
WHERE condition1 OR condition2 OR condition3 ...;
NOT
SELECT column1, column2, ...
FROM table_name
WHERE NOT condition;
Order By
ORDER BY se používá k seřazení záznamu vzestupně a sestupně
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;
Insert Into
Insert into se používá do vkládání nový záznamů do tabulky. Dá se psát dvouma způsoby
- Specifikujeme do jakého sloupce chceme vložit jaké hodnoty
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
- A pokud chceme přidat hodnoty do všech sloupců v tabulce tak nepotřebujeme specifikovat sloupce. A případné hodnoty zapisujeme v pořadí sloupců
INSERT INTO table_name
VALUES (value1, value2, value3, ...);
Null Values
NULL je pole co nemá hodnotu S NULL nemůžeme používat s porovnávacími operátory jako =, <, <>. Místo toho se používá IS NULL nebo IS NOT NULL místo toho.
IS NULL
SELECT column_names
FROM table_name
WHERE column_name IS NULL;
IS NOT NULL
SELECT column_names
FROM table_name
WHERE column_name IS NOT NULL;
Update
UPDATE se používá když chceme změnit existující záznam v tabulce
Dávat si pozor: ==WHERE specifikuje jaký záznam má být aktualizován nebo jaké záznamy mají být aktualizované ale když se WHERE vynechá tak se aktualizují všechny záznamy v tabulce==
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;
Delete
DELETE se používá k odstranění existujících záznamu v tabulce
DELETE FROM table_name WHERE condition;
Select Top
SELECT TOP se používá pro specifikaci počtu záznamů co se vrátí při provedení
SELECT TOP number|percent column_name(s)
FROM table_name
WHERE condition;
Min a Max
MIN()
MIN vrací nejmenší hodnotu ve vybraném sloupci
SELECT MIN(column_name)
FROM table_name
WHERE condition;
MAX()
MAX vrací největší hodnotu ve vybraném sloupci
SELECT MAX(column_name)
FROM table_name
WHERE condition;
Count, Avg, Sum
Count
Count vrací počet řádku které splňuje specifikované kritérium
SELECT COUNT(column_name)
FROM table_name
WHERE condition;
Avg
AVG vrací průměrnou hodnotu ve sloupci
SELECT AVG(column_name)
FROM table_name
WHERE condition;
Sum
SUM funkce sečte všechno v sloupci a vrátí
SELECT SUM(column_name)
FROM table_name
WHERE condition;
In
IN nám dovoluje dále specifikovat více hodnot ve WHERE ===Operátor IN je zkratka pro více podmínek OR.===
- První způsob zapsaní
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);
- Druhý způsob zapsání
SELECT column_name(s)
FROM table_name
WHERE column_name IN (SELECT STATEMENT);
Příklad
Tento příklad vybere všechny zákazníky, kteří se nacházejí v "Germany", "France", "UK":
SELECT * FROM Customers
WHERE Country IN ('Germany', 'France', 'UK');
Between
BETWEEN vybere rozsah mezi dvěmi hodnotami.
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;
Příklad
Tento SQL příkaz vybere všechny produkty co mají cenu mezi 10 až 20
SELECT * FROM Products
WHERE Price BETWEEN 10 AND 20;
Aliases
- SQL Alias dává tabulce nebo sloupci dává dočasné jméno
- Většinou se používá pro lepší přehlednost sloupců
- Aliasy existují jen po dobu provádění daného dotazu
- První možný způsob psaní
SELECT column_name AS alias_name
FROM table_name;
- Druhý způsob psaní
SELECT column_name(s)
FROM table_name AS alias_name;
Joins
JOIN slouží ke spojení řádků ze dvou nebo více tabulek na základě příbuzného sloupce mezi nimi.
Příklad
Máme tyto dvě tabulky Jde vidět že mají stejné CustomerID
| OrderID | CustomerID | OrderDate | | ------- | ---------- | ---------- | | 10308 | 2 | 1996-09-18 | | 10309 | 37 | 1996-09-19 | | 10310 | 77 | 1996-09-20 |
| CustomerID | CustomerName | ContactName | Country | | ---------- | ---------------------------------- | -------------- | ------- | | 1 | Alfreds Futterkiste | Maria Anders | Germany | | 2 | Ana Trujillo Emparedados y helados | Ana Trujillo | Mexico | | 3 | Antonio Moreno Taquería | Antonio Moreno | Mexico |
==Všimněte si, že sloupec "CustomerID" v tabulce "Orders" odkazuje na "CustomerID" v tabulce "Customers". Vztah mezi oběma výše uvedenými tabulkami představuje sloupec "CustomerID".==
Pak můžeme vytvořit následující příkaz SQL (obsahující spojení INNER JOIN), který vybere záznamy se shodnými hodnotami v obou tabulkách:
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
A tento SQL dotaz nám vyprodukuje toto
| OrderID | CustomerName | OrderDate | | ------- | ---------------------------------- | ---------- | | 10308 | Ana Trujillo Emparedados y helados | 9/18/1996 | | 10365 | Antonio Moreno Taquería | 11/27/1996 | | 10383 | Around the Horn | 12/16/1996 | | 10355 | Around the Horn | 11/15/1996 | | 10278 | Berglunds snabbköp | 8/12/1996 |
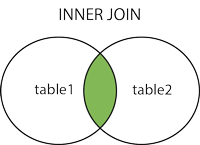
Inner Join
- INNER JOIN vybere záznamy, které mají shodné hodnoty v obou tabulkách. ==Vrací pouze ty řádky, které mají shodné hodnoty ve spojovaných sloupcích obou tabulek. Ostatní řádky, které nemají shodné hodnoty, nejsou zahrnuty ve výsledku.==
SELECT column_name(s)_
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;
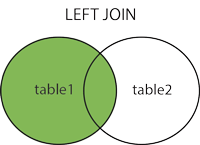
Left Join
- LEFT JOIN vrátí všechny záznamy z levé tabulky (tabulka1) a odpovídající záznamy z pravé tabulky (tabulka2). Výsledkem je 0 záznamů z pravé strany, pokud neexistuje žádná shoda. ==Vrací všechny řádky z levé tabulky a shodné řádky z pravé tabulky. Pokud není v pravé tabulce shoda, jsou přiřazeny NULL hodnoty.==
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;
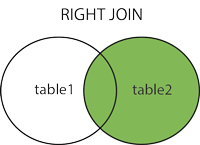
Right Join
- RIGHT JOIN vrátí všechny záznamy z pravé tabulky (tabulka2) a odpovídající záznamy z levé tabulky (tabulka1). Výsledkem je 0 záznamů z levé strany, pokud neexistuje shoda. ==Vrací všechny řádky z pravé tabulky a shodné řádky z levé tabulky. Pokud není v levé tabulce shoda, jsou přiřazeny NULL hodnoty.==
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;
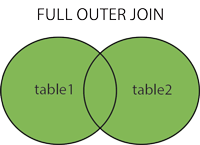
Full Join
- FULL OUTER JOIN vrátí všechny záznamy, pokud existuje shoda v levém (tabulka1) nebo pravém (tabulka2) záznamu tabulky. ==Vrací všechny řádky z obou tabulek a přiřazuje NULL hodnoty pro neshodné řádky.==
SELECT column_name(s)
FROM table1
FULL OUTER JOIN _table2
ON table1.column_name = table2.column_name WHERE condition;
Self Join
- Self Join je běžné spojení, ale tabulka je spojena sama se sebou. ==Self Join je možné pomocí aliasů pro tabulky, abychom odlišili dvě instance téže tabulky. Self join se obvykle používá, když tabulka obsahuje sloupce, které odkazují na jiné řádky v téže tabulce, například přes klíčové sloupce s cizím klíčem.==
Group By
- GROUP BY seskupí řádky se stejnými hodnotami do souhrnných řádků, například "zjistit počet zákazníků v jednotlivých zemích".
- Příkaz GROUP BY se často používá s agregačními funkcemi (COUNT, MAX, MIN, SUM, AVG) ke seskupení výsledné sady podle jednoho nebo více sloupců.
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);
Having
HAVING byla do jazyka SQL přidána, protože klíčové slovo WHERE nelze použít s agregačními funkcemi.
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s);
Insert Into Select
- INSERT INTO SELECT zkopíruje data z jedné tabulky a vloží je do jiné tabulky.
- Příkaz INSERT INTO SELECT vyžaduje, aby se datové typy ve zdrojové a cílové tabulce shodovaly.
Zkopírování všech sloupců z jedné tabulky do jiné tabulky:
INSERT INTO table2
SELECT * FROM table1
WHERE condition;
Kopírování pouze některých sloupců z jedné tabulky do jiné tabulky:
INSERT INTO table2 (column1, column2, column3, ...)
SELECT column1, column2, column3, ...
FROM table1
WHERE condition;
Null Functions
IFNULL()
Pokud je první výraz (expr1) NULL, vrátí druhý výraz (expr2). Pokud není první výraz NULL, vrátí hodnotu prvního výrazu.
SELECT IFNULL(column_name, 'Default Value')
AS new_column
FROM table_name;
ISNULL()
Vyhodnocuje, zda je výraz (expr) NULL. Vrátí 1, pokud je výraz NULL, nebo 0, pokud není.
SELECT column_name, ISNULL(column_name, 'Default Value')
AS new_column
FROM table_name;
COALESCE()
Vrátí první nenulový výraz ze seznamu výrazů. Pokud jsou všechny výrazy NULL, vrátí hodnotu NULL.
SELECT COALESCE(column_name, 'Default Value')
AS new_column
FROM table_name;
NVL()
Pokud je první výraz (expr1) NULL, vrátí druhý výraz (expr2). Pokud není první výraz NULL, vrátí hodnotu prvního výrazu.
SELECT NVL(column_name, 'Default Value')
AS new_column
FROM table_name;